Which reinforcement learning algorithm is typically utilized during the RL Fine-Tuning stage of RLHF?
Answer
Proximal Policy Optimization (PPO)
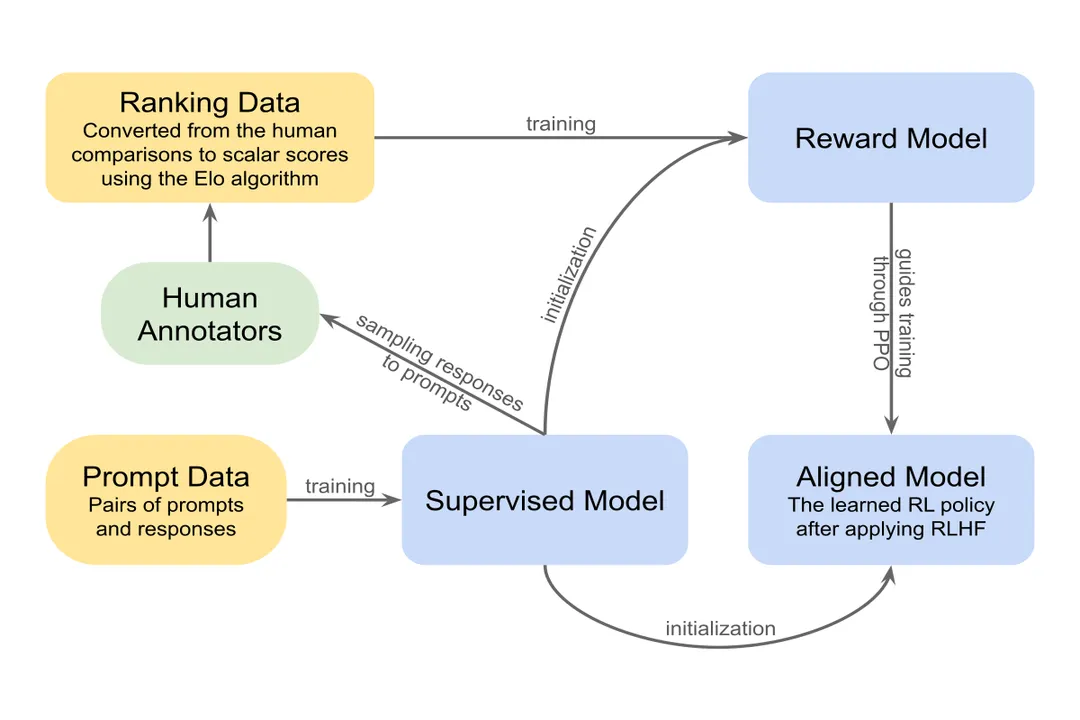
During the third stage of Reinforcement Learning from Human Feedback (RLHF), the fine-tuning of the original large language model is typically executed using the Proximal Policy Optimization (PPO) algorithm. PPO is favored in this context because it offers a good balance of stability and sample efficiency compared to some older policy gradient methods. In this step, the LLM acts as the policy, and it is updated based on the reward signals provided by the previously trained Reward Model (RM), effectively steering the model's output generation capabilities toward maximizing human preference scores.
Related Questions
Who established Reinforcement Learning as a distinct field with their seminal textbook?What function does the Reward Model (RM) serve in the Reinforcement Learning from Human Feedback (RLHF) process?What specific level did EACL 2006 research focus RL on for learning optimal dialogue strategies?What essential concept must an RL agent learn to maximize over a sequence of interactions?What major award did Richard S. Sutton and Andrew G. Barto receive in 2023?Why is Temporal-Difference (TD) learning considered significant in RL research?Regarding LLM dialogue agents, what characteristic defines their action space?Which reinforcement learning algorithm is typically utilized during the RL Fine-Tuning stage of RLHF?How does the objective learned via RL in dialogue differ from supervised learning next-token prediction?To what mathematical concept pioneered by Richard Bellman does RL owe its structural foundation for sequential decisions?