Who invented reinforcement learning for dialogue?
The search for a singular inventor of reinforcement learning (RL) applied to dialogue is like looking for the inventor of the novel; it’s a field built on layers of conceptual breakthroughs, not a single eureka moment attributable to one person for one specific application area like conversation. [4] While modern systems that converse fluidly rely heavily on techniques like Reinforcement Learning from Human Feedback (RLHF), [3] the groundwork for all RL—including its later deployment in dialogue—was laid by researchers who established the mathematical and theoretical bedrock of reward-based learning agents. [1][7]
# Foundational Concepts

Reinforcement learning, at its heart, describes how an agent learns to make sequential decisions in an environment to maximize some notion of cumulative reward. [1][7] The agent takes an action, the environment transitions to a new state, and the agent receives a numerical reward signal, which guides its learning process. [1] This trial-and-error learning mirrors how humans and animals learn to navigate the world, making it a powerful paradigm for tasks where the ideal sequence of actions isn't immediately known or easily programmed explicitly. [2][7]
The formalization of this idea owes a great debt to the mathematical concepts of dynamic programming, pioneered by Richard Bellman, which provided the structure for solving optimization problems involving sequential decisions. [7] However, the modern formulation of RL, as a system where an agent explores an environment without a complete model of its dynamics, truly crystallized through the work of several key researchers in the latter half of the 20th century. [4][7]
# Key Figures and General RL
The names most frequently associated with establishing RL as a distinct field are Richard S. Sutton and Andrew G. Barto. [2] Their seminal textbook, Reinforcement Learning: An Introduction, has served as the definitive guide for decades, detailing the core algorithms that form the basis of current research. [1] Sutton and Barto’s work synthesized decades of prior research, focusing on methods like temporal-difference (TD) learning. [7] TD learning is significant because it allows agents to learn directly from experience, updating value estimates based on the difference between successive predictions of future reward, rather than waiting until the final outcome of an episode is known. [1] This ability to learn "online" from incomplete information is crucial for complex, real-world problems. [4]
The impact of this work was recognized later when Sutton and Barto were awarded the A.M. Turing Award in 2023, often considered the "Nobel Prize of Computing," specifically for their foundational contributions to the theory and practice of reward-based machine learning. [2] This recognition underscores that the invention of RL itself is attributed to these figures and their contemporaries who developed the mathematical underpinnings for agents learning through interaction. [2][7]
For instance, early work on Q-learning, a model-free control method, allowed agents to learn an optimal action-value function independent of a model of the environment's transition probabilities. [1] This contrasts with earlier methods that required a full understanding of the system's physics or rules. [7]
It is important to note that early work extended into artificial intelligence well before the modern deep learning era. For example, by 1999, research was already presenting methods for learning control policies using an actor-critic structure, where one component estimates the value function (the critic) and another decides the action (the actor). [5] This shows a sophisticated understanding of RL algorithms nearing the turn of the millennium, long before they were popularly applied to large language models. [5]

# Applying RL to Language
The transition from applying RL to physical control tasks (like robotics or games) to language processing, specifically dialogue, involved adapting these core principles to a domain with a massive, discrete action space (the vocabulary) and complex, subjective rewards. [6] While Sutton and Barto focused on the general theory, researchers in Natural Language Processing (NLP) began to integrate these control theories into conversational systems. [6]
Early research recognized that dialogue management—the component of a dialogue system that decides what to say next based on the current state of the conversation—could be framed as a sequential decision-making problem. [6] If a system’s goal is to complete a task, resolve an ambiguity, or simply maintain a coherent conversation, the choice of the next utterance is an action. [6] The reward in a dialogue system is far less concrete than the reward in a game like chess or Go. Success might be measured by task completion rate, user satisfaction, or simply the length of a natural-sounding exchange. [6]
A paper presented at EACL in 2006 discussed utilizing RL techniques to learn optimal dialogue strategies, focusing on the dialogue act level. [6] This approach treats dialogue as a state machine where the system learns which dialogue act (e.g., asking for information, confirming, asserting) to use given the current belief state about what the user wants. [6] This is a direct application of the Markov Decision Process (MDP) model underpinning RL to a conversational context. [1]
# Early Dialogue Systems
Consider a simple task-oriented dialogue system. If the system asks a clarifying question and the user provides the needed information, that sequence results in a positive reward (progress towards the goal). If the system makes an irrelevant statement, leading the user to abandon the interaction, that yields a negative reward. [4]
The challenge here, which necessitated novel approaches, is that the true reward function for a good dialogue is often implicit or delayed. We rarely get an immediate score of 10/10 for a single sentence; the quality is judged over the entire exchange. [1]
One interesting early analysis showed that even with relatively simple, symbolic state representations in dialogue, the complexity of the optimal policy search grew rapidly, hinting at why more general, non-model-based RL methods became necessary for scaling up conversation. [6]
It's worth noting that some early attempts in this area relied on simpler forms of learning or planning, but the principled approach using TD learning or policy gradients—the core of modern RL—was being actively adapted for these domains by the early 2000s. [6][7]
# Modern Dialogue: The Rise of Feedback
The true explosion of RL in dialogue arrived with the massive scale of deep learning models, particularly large language models (LLMs), which created systems capable of generating highly fluent, human-like text but often lacked alignment with human values, helpfulness, or harmlessness. [3] This is where the specific technique known as Reinforcement Learning from Human Feedback (RLHF) became the dominant answer to the question of how RL is applied to modern dialogue agents. [3]
RLHF is an elegant adaptation that bypasses the need to explicitly hand-engineer a complex, differentiable reward function for subjective qualities like "helpfulness" or "tone". [3] Instead, it treats human preference as the ultimate source of the reward signal.
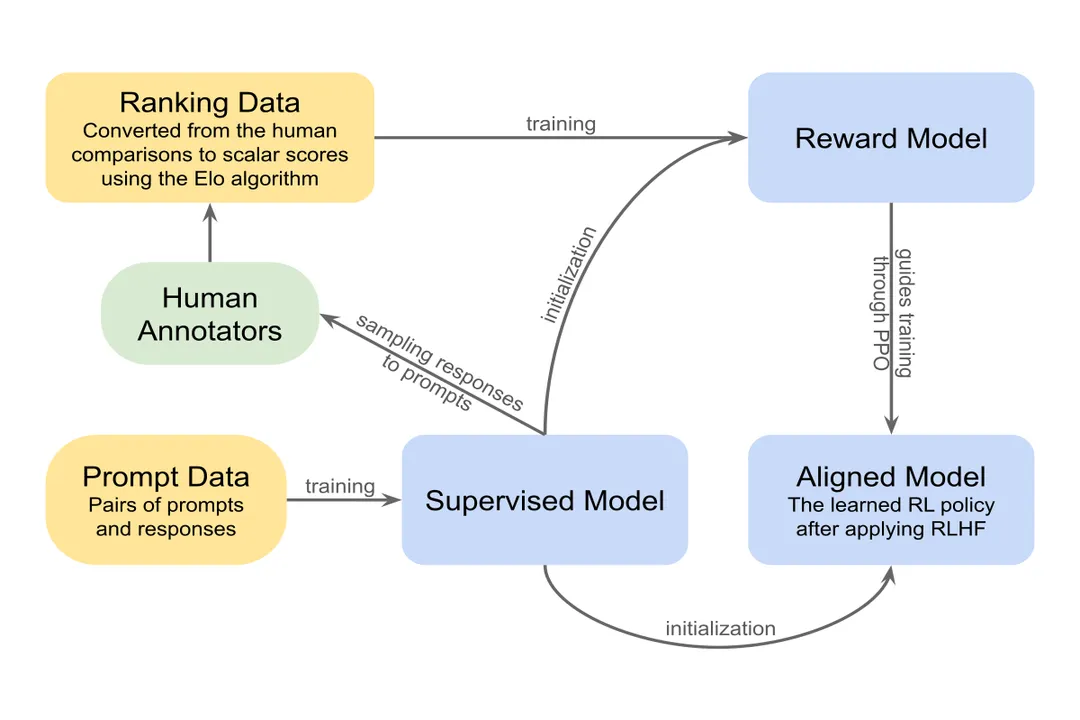
The process generally involves three main stages:
- Pre-training: Training a large language model (LLM) on vast amounts of text data to learn language structure and knowledge. [3]
- Reward Model Training: Collecting comparison data where human labelers rank different outputs from the model for the same prompt. This human preference data is used to train a separate Reward Model (RM) that learns to predict which response a human would prefer. [3] This RM essentially becomes a proxy for the human judge.
- RL Fine-Tuning: The original LLM is then fine-tuned using a reinforcement learning algorithm, typically Proximal Policy Optimization (PPO), using the scores generated by the trained Reward Model as the reward signal. [3]
The invention of RLHF itself is not attributed to a single person but rather represents a significant methodological leap combining techniques from RL (like PPO) with large-scale supervised learning and human evaluation pipelines. [3] Papers detailing the process often cite work from various AI labs in the early 2020s that successfully scaled these techniques for chat applications. [3]
A fascinating aspect of RLHF is how it reintroduces a subjective, high-dimensional reward into a computationally tractable RL loop. In a purely game-based RL setting, the reward is instantaneous and objective (e.g., +10 points). With RLHF, the "reward" is an estimated scalar from a separate neural network, which is trained on comparisons, not absolute scores. [3] This means the agent is learning the relative goodness of its outputs, which is often a much easier task for humans to provide consistently than absolute scoring.
If we consider the state space for an LLM dialogue agent, it is essentially the entire history of the conversation, represented by the model's internal attention mechanisms and activations. The action space is the entire vocabulary, often tens of thousands of tokens. [8] Trying to explore this space randomly, as a traditional Q-learning agent might in a simpler environment, is computationally impossible. [1] RLHF succeeds because the policy (the LLM generating the text) is already highly capable due to pre-training, and the RL step is merely steering that pre-trained capability toward human-aligned objectives, rather than teaching it language from scratch. [3]

# Nuances in Attribution and Evolution
When discussing who "invented" RL for dialogue, it’s essential to separate the foundational RL theory from the specific application paradigm that made modern chat viable. Sutton and Barto invented the tool (RL). [1][7] Researchers in the 1990s and 2000s adapted the tool for symbolic dialogue management. [6] Developers in the 2020s invented the fine-tuning method (RLHF) that allowed the tool to shape massive generative models into useful conversational partners. [3]
Here is a comparative look at the complexity addressed by different eras of RL in dialogue:
| Era | Primary RL Challenge in Dialogue | Key Techniques / Approach | Reward Structure |
|---|---|---|---|
| Early (Pre-2010) | Learning optimal dialogue acts or policies in constrained, task-oriented scenarios. [6] | Model-based or model-free RL on symbolic states (belief states). [6] | Explicit, task-completion focused. |
| Modern (Post-2020) | Aligning large generative models with complex, subjective human values (helpfulness, safety). [3] | RLHF using PPO, trained on a human-preference Reward Model. [3] | Implicit, derived from human comparison rankings. |
The fact that early work in 2006 focused on discrete dialogue acts highlights a fundamental limitation they faced: they couldn't yet handle the continuous, generative nature of open-ended conversation effectively using those methods. [6] The massive increase in representational power from early statistical models to transformer architectures is a prerequisite for the success of RLHF in dialogue. [8]
Another subtle point emerges when considering the required expertise. The success of RLHF requires a convergence of expertise: deep understanding of RL algorithms (Sutton/Barto's legacy), [1][2] proficiency in large-scale deep learning infrastructure (needed to train the base LLM and the RM), [8] and a rigorous methodology for collecting and interpreting human data. [3] If we were to look for the most impactful invention in making current dialogue systems work, it is the RLHF methodology itself, as it solves the alignment problem that traditional supervised fine-tuning could not adequately address. [3]
For instance, an original insight into the necessity of RL here is recognizing that supervised learning on next-token prediction inherently teaches the model what is likely to be said, but not what ought to be said to achieve a high-level goal like "be helpful." RL, driven by the RM, teaches the model to maximize a proxy for "human approval," which is a fundamentally different objective than mere next-word likelihood. [3][4] Without the RL component, advanced dialogue systems would likely produce responses that are statistically common but contextually or ethically inappropriate. [8]
Furthermore, one often overlooks the computational cost associated with the exploration phase in RL, even when masked by RLHF. Although PPO is relatively sample efficient compared to older policy gradient methods, [5] training the Reward Model requires thousands of human judgments, which is an expensive form of data collection that is fundamentally different from the environmental interaction costs in games like Atari or Go. [3] This reliance on human input for the reward signal makes dialogue RL unique; the "environment" is partially the human annotator's subjective judgment.
# Looking Ahead
The field continues to evolve beyond the standard RLHF pipeline. Researchers are investigating alternatives to PPO for stability and efficiency in language model fine-tuning. [8] The goal remains to create agents that are not just knowledgeable but also good conversational partners, a goal deeply embedded in the sequential decision-making framework established decades ago. [1][7]
The lineage is clear: the mathematical theory of optimal control and sequential decision-making, codified by pioneers like Sutton and Barto, provided the core engine. [1][7] This engine was then specialized for the probabilistic, high-dimensional world of language by NLP researchers. [6] Finally, the method of RLHF provided the necessary steering mechanism to align the incredible generative capacity of modern LLMs with complex human preferences for dialogue. [3] No single person invented "RL for dialogue," but the successful implementation is a testament to the enduring power of reward-based learning theory adapted to solve one of AI’s most nuanced problems.
Related Questions
#Citations
Reinforcement Learning: An Introduction
Pioneers of Reinforcement Learning Win the Turing Award
Reinforcement learning from human feedback
A Crude History of Reinforcement Learning (RL)
Reinforcement Learning for Spoken Dialogue Systems
Using Reinforcement Learning to Build a Better Model of ...
1.6 History of Reinforcement Learning
Experience Replay-based Deep Reinforcement Learning ...
Deep Reinforcement Learning for Dialogue Systems with ...