How does the objective learned via RL in dialogue differ from supervised learning next-token prediction?
RL teaches the model to maximize a proxy for human approval, not just what is statistically likely.
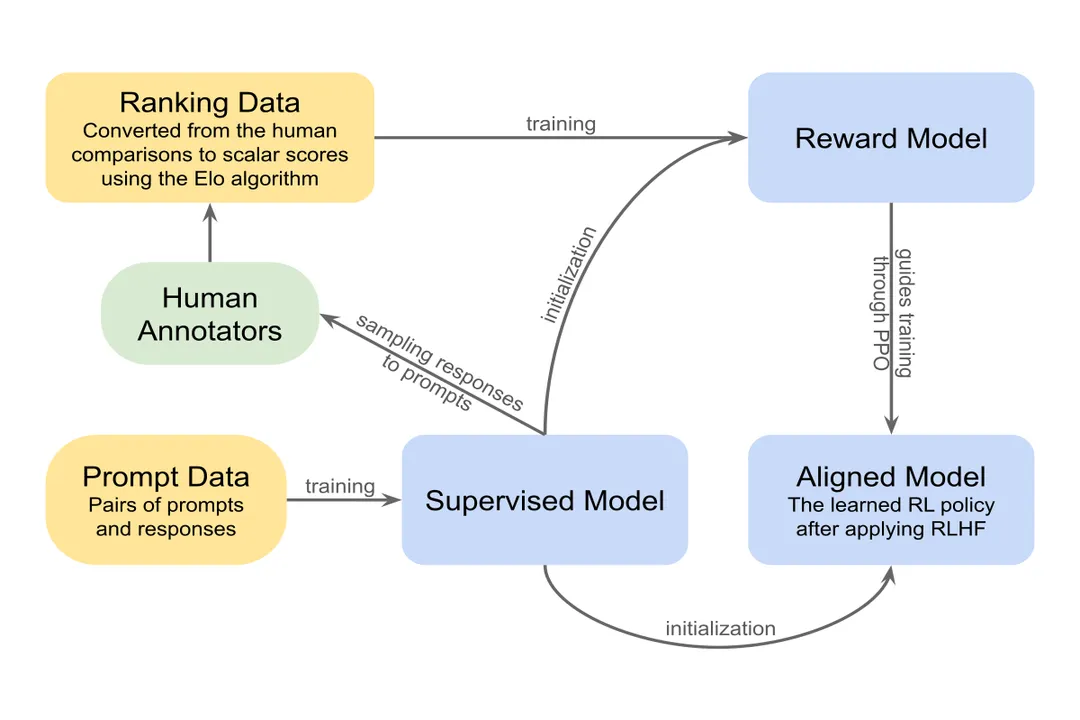
The fundamental difference lies in the objective function. Supervised learning, applied via next-token prediction during pre-training, teaches the model to reproduce responses that are statistically common or likely based on the training data. In contrast, the RL component driven by the Reward Model teaches the agent to maximize a proxy for 'human approval,' such as helpfulness or safety, which is a fundamentally different, high-level objective. Without the RL steering mechanism, advanced dialogue systems risk generating responses that are fluent but contextually or ethically inappropriate because they have only learned what *is* likely to be said, not what *ought* to be said to achieve a desired communicative goal.